

The State of College Basketball Technology
How Data, Analytics, and Software Development are the Next Frontier

Modern sports analytics started not in basketball, but in baseball, when Bill James began publishing a series of books titled Baseball Abstract in 1977. Baseball naturally breaks into measurable states and isolated events, which made statistical modeling much easier than basketball’s continuous-flow environment.
The intellectual foundation of these topics expanded greatly in the 1990s thanks to the advent of internet communities. Billy Beane and the Oakland Athletics operationalized some of the concepts in the early 2000s and became culturally famous for it thanks to Michael Lewis’s 2003 book, Moneyball.
Around that time, an early basketball analytics movement had started to form. John Hollinger released Pro Basketball Prospectus in 2002, a spiritual sibling to James’s Baseball Abstract. The online community APBRmetrics became the go-to forum for debate around these ideas, and from that movement, Dean Oliver released Basketball on Paper in 2004.
That same year, Oliver joined the Seattle SuperSonics as Director of Quantitative Analysis.1 But it was the Houston Rockets who became the first NBA front office to fully embrace analytics as an organizational philosophy, prioritizing quantitative thinking in their search for a new general manager and eventually selecting a young consultant for the Boston Celtics, Daryl Morey.2
Twenty years later, every NBA franchise employs not only analytics professionals, but full engineering and research teams with expertise in data engineering, computer vision, biomechanics, machine learning, and AI tools. And if this is now the path toward competitive advantage in basketball, a compelling question emerges: “How can a college basketball program realistically build such an ecosystem?”
I have long followed the NBA Salary Cap and roster construction as a hobby. Last summer, I had the opportunity to take part in Sports Business Classroom (SBC) at NBA Summer League in Las Vegas.3 Following one session, I was fortunate enough to be part of a small group that got about a half hour with one high-ranking NBA executive.
Aside: I do not pretend to be a journalist and no one I have spoken to intended to be “on-the-record” during our conversations so I will be referring to them anonymously. Furthermore, any conclusions here are my own, using conversations I have had only as background.
One question I wanted to get to the root of was “How does an NBA franchise coordinate all the different groups (coaching, player development, player health, scouting, cap management, etc.)?” A front office could have engineers in a single team and then assign them to each of those groups or each group could have their own engineers that may or may not come together to share best practices. In engineering, we would call this functional organizational structure versus matrix structure.
This NBA executive perked up at the question and confirmed what I had already expected, that their organization experienced significant friction in this area, common among growing startups. He referred to what he and his team have identified as “Tech Ops”, an emerging need to align all of these areas under a unified direction.
He stated that he believed his organization had one of the smaller groups comparatively at roughly 25 people. Later, as part of a basketball analytics course I was taking, I was able to discuss this topic with a guest speaker from an NBA analytics group (not from the Suns). He indicated that their data science team alone was currently at 15 and looking to hire two more this offseason.
Engineering teams don’t have a salary cap in the NBA4, so if you have money to spend and winning is what matters, that’s one place to spend it. It is not unreasonable to think that some organizations will house engineering teams of over 50 people by the end of the decade.5
But despite the growing demand, these jobs are extremely difficult to get. The supply of people wanting to work in the NBA is enormous and teams typically hire unpaid or very low-paid interns and promote from there. It is a battle just to get a foot in the door.
However, in that same summer league, I also had the opportunity to speak to a couple of people from college basketball programs, only then realizing that most are just now entering their technological awakening, akin to the NBA twenty years ago.
To get a better lay of the land, I set out to speak to as many members of college basketball programs as I could. It is still a small sample size, but I was able to chat with people in varying roles, from high-D1 to low-D1 to lower levels, and both men’s and women’s teams. Here is what I have found so far.
Since many of my articles involve the University of Arizona, I want to specifically state that I am not using any conversations with any member of the Arizona staff to inform this article.
College Front Offices
Do programs have dedicated front office personnel that work on data strategy, analytics, and roster optimization?
To answer that question, we should first ask what a college basketball staff has looked like traditionally. I grew up in the 1990s, when even high major teams typically employed only a head coach, three assistants, a director of operations, possibly a graduate assistant, and a group of maybe four managers.
At that time, there were much stricter NCAA rules about the number of coaches, so roles like Ops Director were additional ways that programs could shoehorn in another coach in addition to their operations duties. Over time, other roles became a part of the “coaching” staff, including strength and conditioning coaches and player development specialists. I have personally seen athletic trainers and even one team chaplain that acted as a statistician for his team during games.
But the typical entry level job, whether a senior manager or GA or entry-level coaching hire, was and seems to still remain, video coordinator. At one time, this meant manning two VHS players to play game film on one while recording clips onto another. Today, that job is done in much more advanced software systems.
Those systems seem to be the primary data hub for most programs. So what you see now are roles such as Director of Video and Analytics, although titles vary from program to program. From my research, programs currently enlist between zero and two staff members who study data and analytics as part of their primary responsibilities.
Furthermore, nearly all of these people are not professional engineers; they are young coaches. This is really the break from the NBA structure. Whereas NBA front offices might have people building this skillset for decades, most point-people for analytics on coaching staffs are in that role only for one or two years before moving to an assistant coach position elsewhere.
This may be changing. As one example, Illinois is recruiting interns in this area for the upcoming season.
While the hiring of analytics professionals might be lagging, college programs have been quicker to adopt the General Manager role, albeit typically with the GM effectively reporting to the head coach, the opposite of the NBA structure. Noah Henderson keeps a list of college basketball executives here.
These roles have different responsibilities from program to program but could include NIL management, recruiting coordination, oversight of analytics, scheduling, or many other responsibilities. This is an evolving area that it seems a lot of programs are still feeling out.
Do programs use consulting services?
Since most programs use the point-person approach, I thought it was reasonable to ask whether they were getting outside help. This was where I started to see a divide between the haves and the have-nots and the most commonly referred to entity was HD Intelligence (HDI), who tout more than 100 Division I clients.

One of my classmates last summer was working for HDI and showed me some of the reporting he was creating to evaluate the transfer portal for a power conference client. HDI’s value-add is not their analysis alone, but rather how they can tailor their service specifically to each customer.
That being said, I do have concerns about how much information is duplicated from client to client, negating some of the competitive advantage. For HDI’s potential customers, the implied message is not that it is a way to get ahead, but rather a requirement to keep up.
What technology stack are programs using?
In discussions with an NBA director of basketball research, the paraphrased answer I received to this question was “R, Python, Cursor, Snowflake, Databricks, Tableau”. None of these surprised me for an enterprise data science and software development group. Also unsurprisingly, no college program representative answered the question in this manner.
College staff members were instead eager to tell me all of the products they use, typically in a software-as-a-service (SaaS) agreement. The same implied message that HDI pushes is being used by a host of other software vendors: “you need this tool to keep up with the Joneses”.
So what tools are teams using? Every team uses some video platform. HUDL is the dominant uploading and sharing product. Teams also use Synergy or MyVideoAnalyser (cheaper alternative) for more advanced play tagging.
Synergy is improving their abilities in automated analysis thanks to computer vision; however, as you can see by the sales-oriented response to comments, there is a lot of tier-ing of offerings.
Another camera-assisted technology comes from Noah Basketball, with their flagship area of expertise being shooting analysis. I also had multiple responses for ShotTracker, which is a sensor-based system.
Positional data still pales in comparison to the tracking data NBA teams have with Second Spectrum, but companies continue to innovate in this area to try to provide budget friendly alternatives, be it by camera or technology like ultra-wideband tags. Only one person I spoke with said their team uses player tracking for every practice year-round. Catapult is also trying to get into the positional data market after building a customer base in player health and load monitoring.
Many teams also report using Just Play as their team playbook and communications management tool, although I believe they will face increased competition from HUDL and/or Teamworks in this area. All the above tools would likely be used by both coaches and players. But there is another class of tools that are also growing for roster management that would be for front office type staff members only.
The first I will mention is Evan Miyakawa’s Front Office Suite. Evan runs one of the best college basketball websites out there, along with CBB Analytics, and KenPom to name a few. This past season, he also released a package of roster tools for NIL valuation as a part of roster construction. No team I spoke with said they used this product, but Evan has stated on his podcast that his first customer last year was Michigan, who went on to win the National Title. The Wolverines also hired a Director of Basketball Analytics at that time.6
The leading company in the roster area is Dropback. Originally developed as a financial management tool for football, it has expanded to basketball and is trying to emphasize analytics by integrating with other data companies so their outputs can be incorporated into the Dropback user interface.
How is all this data managed?
In my opinion, not well. And this flows from what I consider to be a fairly common engineering anti-pattern, a reliance on Technology-Driven Design. Simply stated, instead of deciding “what do I require?” and then selecting tools, users ask “what tools do I have at my disposal?” and then determine what problems those tools can solve.
For example, I asked people I spoke with whether their teams stat items that don’t appear in the boxscore either in games or practices (e.g., screen assists, paint drives, shots affected). Every team answered yes to this question to some degree. But when I asked what happens to that data, answers varied greatly.
The most common practice was that it was either reviewed that day, then discarded or that the data was entered into a spreadsheet that lived either on one coach’s laptop or in a shared document library. Obviously, that is not a way to build a long-lived data repository.
So we have information that the coaching staff feels is important enough to track, but not important enough to keep. Why? Because none of the existing tools are set up for it.
Now, if enough customers want a count of ball reversals, Synergy will add a model to identify those and add it to their premium package.7 Then the data continues to live in Synergy, forging an even stronger connection between customer and product.
If you look at NBA front offices or other analytics-focused businesses, the most value is created once the data is retrieved from these systems and modeled independently. And that is really the foundational change I expect to see soon, data ecosystems owned by the universities.8
Even beyond the ad-hoc stat sheets, my hypothesis is that a lot of the data that is generated by third-party products is held in the accounts of the coaches. When a coach leaves, I’m not sure a lot is being done to retain that data. Especially as AI tools continue to improve, the universities should want to keep as much of it as possible. I believe a lot of IP is leaking right now.
While I would be reluctant to rely on another product expansion for this task, it is worthwhile to highlight that Dropback and the University of Kentucky partnered on a database solution earlier this year. So this is a direction that some programs are moving.
How are teams optimizing their rosters?
Let’s assume a program has captured all the data they may need. Now what?
As previously mentioned, there are a number of use cases, including targeting improvements in player development, player health, coaching, or opponent scouting. Another that is critically important is recruiting.
Coaches have long created models to evaluate players, even if they were purely mental models. If a coach looked at boxscore statistics to inform their evaluation, they created a data-based model, even if only subconsciously. This is a good reminder that analytics just means statistics, which have been around and used for decades.
NBA teams have of course taken this much further, using machine learning algorithms and other approaches to create more advanced estimations for use in the NBA draft, free agency, and contract negotiation. Very few college teams claimed they are currently using data to create in-house metrics for evaluation of players.9
Dropback includes the ability to build simple models inside the application’s framework and the suite of tools from Evan Miyakawa include some proprietary all-in-one metrics. However, similar to the issue with HDI, if every team is using the same metrics or models, no one is getting ahead.
Teams with independent models stand to benefit significantly, even if their model is only “as good” as the widely available ones.10 When comparing an independent model to a consensus model, there are four scenarios, with M being the independent model valuation and P being the market price as suggested by the consensus model:
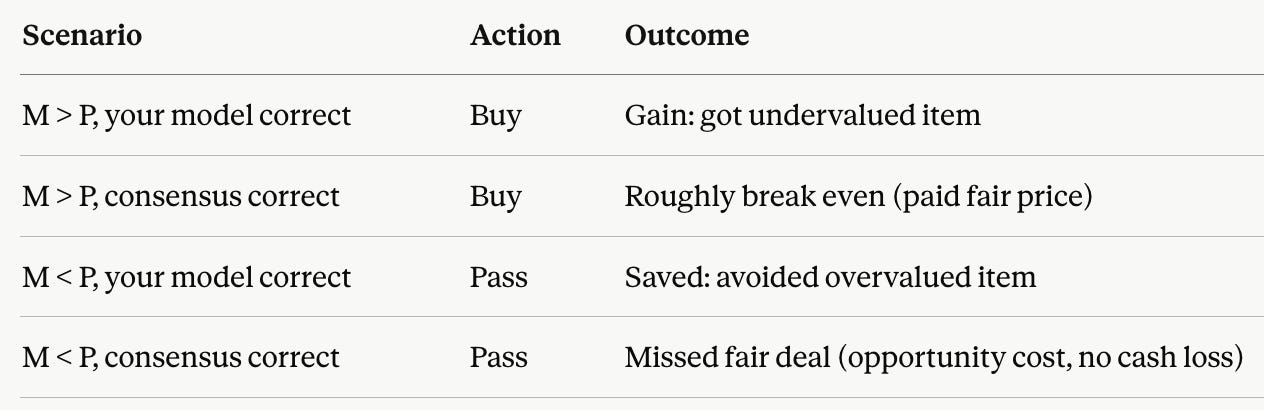
If a team had to bet on every player they evaluate, they would be breakeven as compared to the consensus model. However, they can profitably exploit their disagreement through selective participation. This is a well-understood concept in finance and game theory.
Because there are not four options for players, but 100’s or more, the fourth scenario (missed opportunity) is not a significant loss and even in scenario two, where the consensus model was more accurate, a team’s knowledge of said consensus estimate hopefully keeps them from paying an exorbitant amount.
Now unlike the NBA, as of May 2026, there is not a strict CBA governing roster construction, contract types, and scaled compensation.11 That being said, recruiting has changed immensely in the last few years due to the evolution of pay-for-play, with many now trying to predict an estimation of justified compensation in advance.
Teams can offer opportunity, familiarity, or many other things beyond a dollar figure, but the market is most often driven by the highest bidder, even if not every player eventually chooses the biggest offer. If Team A wants to offer a player and no other team has offered him, that’s a very different negotiating position than if Team B has already made him a big offer.
I asked the people I’ve spoken to whether they have a good idea of what amount of compensation they can offer and if they have an idea what their opponents can offer. On the first question, I got a mixture of answers: on some coaching staffs, it is well understood; on others, that information is tightly held by only a few individuals.
However, nearly everyone said that they believed their head coach had a good idea of what they and their opponents could offer. I would be interested in revisiting this question after this year’s transfer portal. Evan Miyakawa originally projected the market to be up 35% year-over-year but has since revised that number to over 65%. If someone with a broad sense of the market could be off by that much, I find it hard to believe most coaching staff are currently predicting competitors’ budgets accurately enough to gain an advantage in negotiations.
However, that information would be a boon for a team that could put it together. Most is getting back-channeled either from coaches speaking to one another or agents sharing information. Each are actors with their own motivations so verifying that information over time would be essential.
Division I teams that I spoke with ran the gamut from $0 of NIL money to some of the biggest spenders in the country. Sean Miller recently estimated that 20-25 teams will be compensating players to the tune of $20+ million next season. But even for the teams with these massive budgets, they still have to build a functioning team.
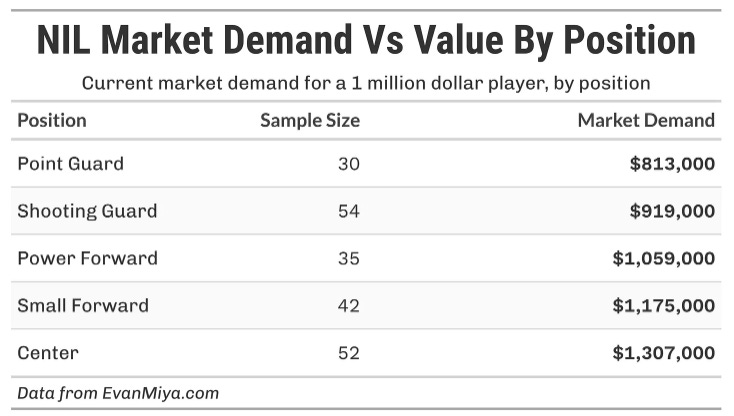
Evan’s compensation estimations clearly did not weight positional differences strongly enough in the initial model as big men have demanded much more than guards this offseason. Of course there are also many different player archetypes at each position, plus fit both on and off the court need to be accounted for.
More than one coach told me that they still value the person they are recruiting as much as the player and talked about the toxicity that could be caused by taking a player solely because he looked like he could be gotten at a discount. To that I would say, put it in the model.
When an NBA team puts together a draft model there is a misconception that the analytics people build a report based on stats, the scouts build a report based on the eye test, and then someone else (coaches, etc.) essentially forms a third report based on “fit”. This is not accurate.
A large part of the work in building an evaluation model is translating subjective qualities to data. For example, a scout might evaluate a guard’s ability to create offense for teammates. Data modelers may ask the scout to directly grade each prospect on this skill or they might look back through notes to estimate a rating. Now that “eye test” factor is in the database and can be used in generating a future model.
If a team has two scouts, they may grade differently, so metadata related to the rating should be retained as well. Over time, with enough data, patterns begin to emerge. It is even better if there are labels on outcomes. Everyone has biases and those can be addressed by reviewing evaluations later on. It’s a significant investment to create such a data set, but one that could pay huge dividends, hence why NBA teams have been codifying scout notes from over a decade prior.
So let’s go back to our hypothetical team from the start of this section. This program has a data infrastructure that includes everything they need to create a player evaluation model that includes both objective and subjective inputs and is independent from widely available models that affect the market price. They have a subset of players that their model believes are undervalued. Now they need to construct their roster, which also can be formulated as a mathematical model.
In operations research12 (the study of optimization), one fundamental class of problems is called the knapsack problem. The name comes from a simple premise: you have a knapsack with a fixed capacity and a collection of items each with a value. The goal is to select the combination that maximizes total value without exceeding the capacity of the bag. In recruiting, the knapsack is the roster, finite in size and constrained in many ways, including budget, and the items are potential players, each carrying a value the model has estimated.
But a roster is not a simple knapsack because players are not independent of one another. A floor-spacing shooter is worth more next to an elite pick-and-roll ball handler than next to another shooter. These interaction effects, positive and negative, are part of what makes roster construction genuinely complex. What separates great roster builders from good ones is often how well they navigate this complexity, whether consciously or by instinct.
Operations research has formal tools to handle these complexities: hard limits, soft preferences, and interaction factors, all within a single mathematical framework. Incorporating coaches’ instinct into a mathematical model makes it repeatable, scalable, and more accurate. Are teams currently doing this? I strongly doubt it.
Why aren’t college programs making a bigger investment?
Nearly every person I spoke to voiced a belief that there was value to improving in these areas. However, they all followed up with some form of “we just don’t have enough time or resources”.13
This is a problem that will only get bigger. College coaching staffs are being stretched in numerous different directions and it does not appear that will change anytime soon. As the number of products in the space grows, it will become more intimidating to try to incorporate them into the workflow, or to create a new one.
Think of all the areas we have touched on in this article: data modeling and database architecture, computer vision and data science, market economics, game theory, AI, and operations research. While the programs employ some of the very best basketball minds in the world, it is unreasonable to expect them to be experts in all of these realms. However, many universities do employ experts in these areas.
So I took this idea one step further, asking “Do you use other resources at the university like professors or students in engineering, computer science, or data science in any collaborative way?”
I had more than one person tell me that they have had professors reach out who wanted to engage, but that it had yet to come to fruition. Others told me it was an idea that they never considered. The only school I have found so far that is currently taking this approach is the University of Florida, who has a Sports Analytics Lab.
While there would be some sport specific differences, some of the areas we’ve discussed (data ecosystem first among them), might be better attacked at the athletic department level rather than program by program. Basketball and football staffs could both benefit from AI training, for example.
If a school’s athletic programs could leverage the expertise of their faculty and student base, the potential benefits are compelling on both sides. Programs that lack the resources to build internal engineering departments could access capabilities that would otherwise be out of reach. Engineering students with interests in sports would have the opportunity to work on real-world problems while still in school. And for universities, the partnership represents a genuine differentiator: a tangible bridge between athletics and academia that could serve as a recruiting tool for both.
The faculty side of this equation is less straightforward. Professors are driven by research funding and publishable work, while concerns about competitive secrecy complicate traditional academic publishing models. These are real obstacles that would require deliberate structural solutions like sponsored research agreements, delayed publication windows, and strict data governance separating methodology research from proprietary team data. The University of Florida’s Sports Analytics Lab suggests a workable model exists. Understanding exactly what that looks like at scale is one of the more important open questions in this space.
Conclusion
The gap between the high major D1 teams and the rest of college basketball is widening. Realistically, there are only a few dozen teams that have the means to make a serious investment in their technological capabilities. But even those programs have a fraction of the resources that an NBA team does.
However, 30 NBA teams are likely not all wrong that there is value to be had in this area. Many college programs do their best to imitate the work done in NBA front offices to varying degrees, but do so mostly through third-party products rather than a cohesive internal strategy.
For most coaching staffs, there is only time and effort available to address the here and now. Many preach a next play or next game mentality which keeps them focused, but few have visions of what they want to be able to do in five or ten years, much less a roadmap on how to achieve that.
There is an investment to be made today that may take time to bear fruit, but the programs/schools that are preparing now will be in the best position come the 2030s. They are also best suited to handle the volatility in the NCAA rules that will occur between now and then.
The investment could come in the form of engineering hires, external services, or partnership with their school’s academic resources. Each has its own pros and cons, but I strongly believe any effort should start with the development of a domain-driven design for a data model.
While there are tons to be gained in better use of on-court analytics, roster optimization will likely be the hottest area as the NCAA continues to try to define what its future will look like. The tools in this specific area are in their infancy, but I am certain there are a couple of schools that are early adopters, experimenting and adapting what they’ve learned.
Finally, it is good to remember that any of these technologies are just that, tools. No tool will replicate the knowledge and instinct of the subject matter experts (SME), in this case basketball players and coaches. But technology is advancing rapidly and as a cautious techno-optimist, I am expecting that it will continue to become more democratized, which is great news for the SMEs.
A former NBA Coach of the Year spoke at SBC last summer and I asked him whether their analytics group brought ideas to him or if the coaches requested specific work from the analytics group. He said it took a long time to get to the point they are now at; that originally, the two groups did not connect. But over time, they built a mutual respect for one another that allowed information to flow equally in both directions with each group understanding the other was an extension of theirs.
It will be some time before college programs reach this level, but they will.
I am still early in my research on this topic. If you know anyone in the college basketball world that would be interested in discussing these topics or others, please let me know or have them reach out to UtterHoops@gmail.com.
The Mavericks and Spurs were also early experimenters in this area.
This is very well documented in a recent oral history on the Sloan Sports Analytics Conference by Alan Siegel and Kirk Goldsberry at The Ringer.
Unlike F1, which is a fascinating structure if you are ever interested
My bet: the new ownership group of the Los Angeles Lakers.
Last week, Michigan Coach Dusty May joined Kevin O’Connor’s podcast and touched on their advancements.
Or if it’s like the 2016-17 Suns tracking high fives, they probably never will.
One of the primary obstacles I received feedback about regarded normalizing the stats of high school recruits at varying levels, versus potential transfers from various conferences, versus international players from various leagues. Although NBA teams also must account for these differences.
Assume both models are unbiased and have equal variance, but uncorrelated errors.
I am of the belief that we will soon see a collectively bargained college basketball league. Whether that occurs in three years or ten, I do not know.
I am biased here because my masters degree focus was operations research. So I kinda just see the world like this.
For context, the rising costs of operation and compensation at the college level still total less than the annual salary of a single NBA player on a max contract.
Agree the next frontier is software, but the bottleneck upstream of it is data quality. Most programs are layering analytics on top of inputs that were never standardized — different devices, different protocols, different definitions of the same metric. As a founder building in athlete data, I’ve watched that turn into expensive dashboards that everyone quietly stops trusting. The programs that win won’t be the ones with the fanciest tools; they’ll be the ones who got disciplined about how the raw measurement is captured in the first place. Clean inputs beat clever models almost every time.
Calling data and software the next frontier in basketball is right, but the frontier I’d watch isn’t the college level - it’s everything upstream of it. By the time a player hits a D1 program the data infrastructure is mature. The gap is the fifteen years before that, where the measurements either get captured and carried forward or they vanish. Whoever solves the youth-to-college handoff for athlete data ends up feeding the whole pipeline you’re describing.